言語モデルはどのように言葉を学習しているのか? 転機となった「word2vec」【土木×AI第25回】:“土木×AI”で起きる建設現場のパラダイムシフト(25)(2/2 ページ)
連載第25回は、目覚ましい進化を続ける生成AIの理解を深めるため、言語モデルに用いる“ニューラルネットワーク”が、どのように言葉を学習しているのかを土木学会の最新研究を引用しながら探ります。
画像に対して質疑応答する「VQA」で生成した「落橋防止システム」
word2vecが登場すると、従来の深層学習の方法と、例えば連載第10回で取り上げた長期記憶を導入した「LSTM(Long Short Term Memory)」などを組み合わせる試みが始まりました。文献7では、下図のように、画像から得られた特徴量と質問文のエンベディングをLSTMに取り入れることで、損傷に対する診断を試みています※7。画像に対して質疑応答を行う仕組みは、「VQA(Visual Question Answering)」と呼ばれています。

下図は、この方法によって生成された「落橋防止システム」と「対傾構の損傷に関する質疑応答」です。図中の緑字が正解で、赤字が不正解を表しています。また、VQAが画像を用いた場合の回答で、QAは画像を用いない質疑応答の場合です。画像を合わせて用いるVQAによって、精度が上がっていることが分かります。

2017年に発表されたトランスフォーマーは、“エンベディング”の技術も取り入れられており、アテンションと組み合わせることで高度な言語処理が実現し、言語モデルの研究開発が急速に進みました※8。その延長上に今の生成AIや大規模言語モデル(LLM)があります。さらに、画像をはじめとした多様なデータと組み合わせることで、「マルチモーダルAI」※9の発展にもつながっています。
※8 土木×AI”で起きる建設現場のパラダイムシフト(19):「ChatGPT」など大規模言語モデルの仕組みと土木領域での可能性【土木×AI第19回】
※9 土木×AI”で起きる建設現場のパラダイムシフト(22):ChatGPTの新機能「GPT-4V」など、言語と画像のマルチモーダルAIを土木に用いるアイデア【土木×AI第22回】

Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 AI:ザハ・ハディドの特徴を捉えた住宅デザインをAIが生成 mignの画像生成サービス
AI:ザハ・ハディドの特徴を捉えた住宅デザインをAIが生成 mignの画像生成サービス
mignは、生成AIで学習したデザインの特徴を踏まえた画像を生成する「stylus」の提供を開始した。数十枚以上の画像をアップロードすると、画像の特徴を解析し、そのデザインを踏まえたイメージが生成できる。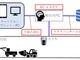 山岳トンネル工事:トンネル坑内作業の状況を画像解析AIが判定、施工管理業務を効率化 清水建設が開発
山岳トンネル工事:トンネル坑内作業の状況を画像解析AIが判定、施工管理業務を効率化 清水建設が開発
清水建設は、山岳トンネル工事の施工管理業務を効率化する情報共有ツール「AIサイクル自動判定システム」を開発した。Webカメラのライブ映像からトンネル坑内作業の状況を画像解析AIで自動判定し、チャットツールを通じて施工関係者へリアルタイムに展開する。 AI:生成AIとIoTで建設現場の“unknown”を無くす!西松建設の工事で4割時短したMODEの頼れるAI部下
AI:生成AIとIoTで建設現場の“unknown”を無くす!西松建設の工事で4割時短したMODEの頼れるAI部下
MODEは、生成AIとIoTのチカラで、建設業界を筆頭に多様な産業の課題解決を目指すスタートアップ企業。IoTのチカラとしては、IoTデータを集約して可視化するプラットフォーム「BizStack」が、前田建設工業など複数のゼネコンで活用されている。今回、生成AIを現場を最もよく知る作業員の部下やアシスタントと位置付けた機能を追加した。先行導入した山岳トンネル工事では、40%の時間削減などの効果が得られているという。 現場管理:正答率94%のAI配筋自動検査システム、大林組が開発 外販も視野
現場管理:正答率94%のAI配筋自動検査システム、大林組が開発 外販も視野
大林組は、ステレオカメラの画像データと生成した点群データを活用したAI自動計測技術により、計測精度と作業効率を向上する配筋自動検査システムを開発した。配筋検査業務の作業時間を現状と比較して約36%縮減する。 温故創新の森「NOVARE」探訪(前編):新たな芽をいつか森に、清水建設がイノベーション拠点でゼネコンの枠を超えて目指す姿
温故創新の森「NOVARE」探訪(前編):新たな芽をいつか森に、清水建設がイノベーション拠点でゼネコンの枠を超えて目指す姿
スマートイノベーションカンパニーを目指し建設を超えた領域でのイノベーションを推進する清水建設。イノベーション創出のための重要拠点として新たに2023年9月に設立したのが「温故創新の森『NOVARE』」だ。本稿では、前編でNOVAREの全体像を紹介し、後編ではDXによる新たな空間創出への取り組みを紹介する。 現場管理:工事写真の撮影/管理を効率化するアプリをアドバンスト・メディアが開発
現場管理:工事写真の撮影/管理を効率化するアプリをアドバンスト・メディアが開発
アドバンスト・メディアは、画像/文字/音声認識を活用して配筋写真撮影の事前準備を省力化するアプリ「AmiVoice 配筋TORUZO」に新機能を追加し、建設工事全般の写真管理を効率化するアプリ「AmiVoice 写真TORUZO」を開発した。